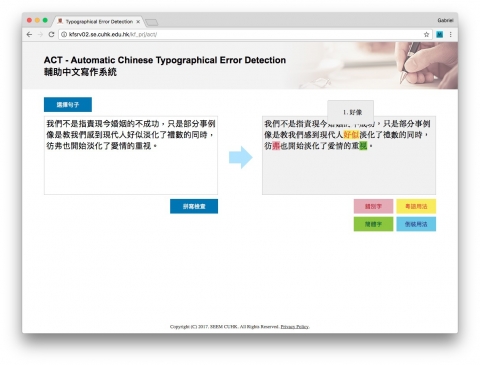
A system called Automatic Chinese Typographical Error Detection has recently been developed by a research team led by Prof. Wong Kam Fai, Department of Systems Engineering and Engineering Management. The system is the first of its kind in Hong Kong for local students. It has already been tested among primary and secondary school teachers and students, and the effect was satisfactory. Colloquial expressions, abbreviations, slang, puns, and emoji have become integrated into daily internet language for teenagers, while social media continues to play an important role in online interactions. Some believe that such internet language has an adverse impact on the written Chinese proficiency of many Hong Kong students. In hopes of improving this problem, the CUHK team proposed an efficient and user-friendly Automatic Chinese Typographical Error Detection system through algorithms based on grand-scale Cantonese language data mining, in-depth calculation, and classification. The pilot system was applied to articles containing a hundred to a thousand words written by primary and secondary school students, and it just took a few seconds to detect error with a low error rate. It detected spelling errors in every sentence and offered replacement suggestions to language learners. The team hopes that in the future the system will be promoted to more primary and secondary schools in Hong Kong as a fun, easy-to-use and useful tool in Chinese language education for students and teachers, and that it will enhance students’ language proficiency. Moreover, the team envisions a brand new add-on to be attached to office software (e.g. Microsoft office) which may become available for public use within this year. The system was recently showcased in the 2017 China Innovation and Entrepreneurship Fair. More accurately identified typos through an intelligent algorithm The system is divided into two parts: typo detection and Cantonese detection. After entering a Chinese sentence or chapter, the system first uses the Typo Detection Module, based on ‘part-of-speech tagging’ and ‘segmentation’, to automatically search for any words which do not fit in the meaning of the sentence. Although some research units also use similar logic for error detection, many common words, such as ‘的’, ‘地’, and ‘是’, are easily misjudged as typos because of the limitations of existing algorithms. Based on big data and deep learning, and in conjunction with a unique intelligent algorithm, the CUHK system is able to identify colloquial usage and inversions in Cantonese language. The team also constructed a confusion set containing over 60,000 Chinese words. With scores being assigned to potential corrections, users are always offered the most suitable replacements. Changing students’ habit of using colloquial expressions The Cantonese Detection Module is a unique feature that detects whether a sentence contains Cantonese colloquial expressions based on a large Cantonese dictionary containing more than 12,000 words, which is still being expanded and optimized. For example, Cantonese language users are inclined to use ‘鍾意’ instead of ‘喜歡’ in the context of preferences. The Detection Module also adopts a rule-based system, the Cantonese linguistic rules of which were described by the team using part-of-speech tagging. Accordingly, the team built a number of rules as a start for basic Chinese sentence structures. Furthermore, the system identifies the usage of quantifiers, such as ‘一條魚/一尾魚’, simplified Chinese, and inversions in sentences, such as ‘緊要/要緊’. The research group of Professor Wong specializes in the research areas of Natural Language Processing, Web Mining, Rumor Detection, etc. ‘We chose Cantonese because of its many special and sophisticated properties, such as a unique grammar system and many colloquial terms, all of which makes the task of detecting errors extremely challenging. We hope that our work will ultimately promote and facilitate Chinese language learning,’ said Professor Wong. ‘It is difficult to set a universal language typographical detection system as the use of language evolves over time and space but we aim at a system with better detection and performance. Deep learning and artificial intelligence are well adopted in the system such that we keep upgrading the word bank and grammar rules based on the changing needs and special requirements of the users or language teachers,’ said Dr. Gabriel Fung, Research Fellow, Department of Systems Engineering and Engineering Management.
|
|